ถึงคราวต้องสร้าง Virtual Machine แล้ว (พื้นฐาน)
เพื่อให้เห็นภาพ ว่าที่ผ่าน ๆ มา มันเป็นอะไร คราวนี้ มาลองสร้าง Virtual Machine กันเถอะ ... มาสรุปสิ่งที่ Virtual Machine ควรจะมีก่อน ... ครั้งนี้คิดสำหรับ process เดียวก่อนนะ
Memory Units
เพื่อให้สามารถสร้าง memory module ได้ เราต้องกำหนดไว้ก่อนว่า แต่ละ word มีขนาดเท่าไหร่ ... สมมติเลยละกันนะ ว่า
ตำแหน่งของ memory 1 ตำแหน่ง จะเก็บข้อมูลได้ 1 byte
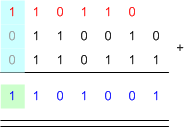
ขนาดของ instruction = 4 byte
ขนาดของ instruction = 4 byte
Process Space
- PC - Program Counter
- Memory - แบ่งเป็น
- Stack
- SP - Stack Pointer
- BP - Base Pointer
- Heap
- MA - Memory Address
- AC - Accumulator
- FP - Frame Pointer
- load: AC ← mem[MA]
- store: mem[MA] ← AC
- push X: SP ← SP - 4; mem[SP] ← X
- pop X: X ← mem[SP]; SP ← SP + 4
ก่อนอื่น ตกลงกันก่อนว่า ส่วนของ OPCODE เราจะยังไม่ใส่ตัวเลขลงไป แต่สมมติว่ามันกินเนื้อที่ 4 byte (เพื่อให้ง่ายเวลา implement จริงเป็นวงจรด้วย) instruction set ที่เราต้องทำ มีสามกลุ่ม คือ
Fundamental Instructions
PUSH X
- คำสั่งนี้ พิเศษกว่าคำสั่งอื่นตรงที่มันมี operand ด้วย ... ดังนั้น ขนาดของคำสั่งนี้จะต้องรวม X ลงไปด้วย ... เราจะกำหนดให้ 4 byte แรกเป็น opcode และ 4 byte หลังคือ X รวมกันเป็น 8 byte ต่อการ PUSH 1 ครั้ง
- การทำงาน: push X
- การทำงาน: push BP
- การทำงาน: pop MA; load; push AC
- การทำงาน: pop AC; pop MA; store
- การทำงาน: pop PC
- การทำงาน: pop AC; if AC > 0, pop PC, else pop AC
- การทำงาน: pop AC; if AC < 0, pop PC, else pop AC
- การทำงาน: pop AC; if AC = 0, pop PC, else pop AC
- การทำงาน: pop AC; if AC ≠ 0, pop PC, else pop AC
- การทำงาน: pop AC; push PC + 4; push BP; BP ← SP; PC ← AC
- การทำงาน: pop AC; SP ← BP; pop BP; pop PC; push AC
คำสั่งในกลุ่มนี้มีสองคำสั่งคือ ALLOC กับ FREE การทำงานของมันจะพิเศษหน่อย เพราะมันเป็น OS-Level Instruction ดังนั้น จะไม่สามารถ implement เป็น hardware ได้ตรง ๆ
ALLOC
- การทำงาน: pop AC; AC ← malloc(AC); push AC
- การทำงาน: pop AC; free(AC)
พวกนี้ จะมีเยอะเท่าไหร่ก็ได้ ... หลัก ๆ จะมีสองกลุ่มคือ unary กับ binary แต่ถ้าจะทำเพิ่ม ก็ทำได้เรื่อย ๆ นะ
NEG
- การทำงาน: pop AC; push -AC
- การทำงาน: pop MA; pop AC; push AC + MA
- การทำงาน: pop MA; pop AC; push AC - MA
- การทำงาน: pop MA; pop AC; push AC * MA
- การทำงาน: pop MA; pop AC; push AC / MA
- การทำงาน: pop MA; pop AC; push AC mod MA
NOT
- การทำงาน: pop AC; push ¬AC
- การทำงาน: pop MA; pop AC; push AC ∧ MA
- การทำงาน: pop MA; pop AC; push AC ∨ MA
- การทำงาน: pop MA; pop AC; push AC ↔ MA
- การทำงาน: pop MA; pop AC; push ¬(AC ↔ MA)
- การทำงาน: pop MA; pop AC; push ¬(AC ∧ MA)
- การทำงาน: pop MA; pop AC; push ¬(AC ∨ MA)
posted by Tunococ @ 6:49 PM
2 comments
![]()
![]()