ร้านกาแฟหกรด

ไปเจอร้านกาแฟนี้ใน San Francisco ชื่อร้านมันตลกมากจนต้องเอามาให้ดู!
posted by Tunococ @ 3:07 PM
9 comments
![]()
![]()
คณิตศาสตร์ ดนตรี คำศัพท์ คอมพิวเตอร์ และ อื่น ๆ อีก (มั่วมาก) มาก
posted by Tunococ @ 3:07 PM
9 comments
![]()
![]()
ไม่ได้เขียนอะไรใน blog นี้ประมาณเวลาตั้งครรภ์ได้ ตอนนี้ใกล้จะกลับไทยแล้ว ก็ขอเขียนซักหน่อยละกัน :P
posted by Tunococ @ 10:21 AM
326 comments
![]()
![]()
จะบอกว่า ถ้าจะดูเรื่องเกี่ยวกะชีวิตนู้บสแตนฟอร์ดเนี่ย ให้ไปดูที่ Another Tunoblog แทน ขี้เกียจ update สองที่หนะ
posted by Tunococ @ 12:45 PM
2 comments
![]()
![]()
เผื่อคนที่ไม่รู้ ตอนนี้อยู่ที่ 119 Quillen Court, #500, Stanford CA 94305 นะ วันจันทร์จะเปิดเทอมแล้ว
posted by Tunococ @ 2:38 PM
3 comments
![]()
![]()
คำอ่าน "Siam Paragon" เป็นภาษาไทยเนี่ย ...
posted by Tunococ @ 11:40 PM
3 comments
![]()
![]()
ขอเริ่มต้น post ของวันนี้ด้วยการขอโทษก่อนละกัน วันนี้ (จริง ๆ เมื่อวานด้วย) ไม่ได้ไปเยี่ยมบัณฑิตจุฬา ฯ ที่ไปซ้อมรับปริญญา เพราะมีเหตุการณ์สำคัญเกิดขึ้นที่บ้าน ที่คนทั่ว ๆ ไปคงเรียกว่าปัญหาครอบครัวหนะ
int fib(int n) { return n <= 1 ? 1 : fib(n - 1) + fib(n - 2); }int fib(int n) { return a[n] > 0 ? a[n] : a[n] = fib(n - 1) + fib(n - 2); } int fib(int n)
{
int f, last1, last2;
if (n <= 1) return 1;
last1 = 1;
last2 = 1;
for (--n; n > 0; --n)
{
f = last1 + last2;
last2 = last1;
last1 = f;
}
return f;
}
posted by Tunococ @ 8:41 PM
3 comments
![]()
![]()
ไม่ยอมเขียนมาซะนาน ขอกลับมาทำบ้างซักครั้งละกัน ... คิดถึงจัง ความรู้สึกนี้ :D
function f(x)
begin if x <= 0 then return 0;
else return 2x - 1 + f(x - 1); end
function f(x)
begin push x onto Stack; push "not done" onto Stack;
while Stack is not empty
do
assign op ← Top of Stack; Remove Top of Stack;
assign x ← Top of Stack; Remove Top of Stack; if op = "not done" then begin
push x onto Stack; push "done" onto Stack;
if x <= 0 then do nothing; else
begin
push x - 1 onto Stack;
push "not done" onto Stack; end end else if op = "done" then
begin
if x <= 0 then assign ReturnValue ← 0; else assign ReturnValue ← 2x - 1 + ReturnValue; end end while
return ReturnValue; end
posted by Tunococ @ 11:31 PM
2 comments
![]()
![]()
โทษทีที่ยังไม่ได้เอารูปตอนไปยุโรปมาลงให้ จะเอามาให้ดูจริง ๆ แหละ แต่รอก่อนนะ ตอนนี้ขอแอบกลับไปเขียนเรื่องบ้า ๆ ต่อก่อน
posted by Tunococ @ 5:07 PM
0 comments
![]()
![]()
ไปผ่าฟันคุดมาเมื่อวันศุกร์ที่แล้วหนะ . . . ผ่าข้างล่างสอง ถอนข้างบนสอง
posted by Tunococ @ 10:18 PM
4 comments
![]()
![]()
หลังจากวันจันทร์ที่แปดแล้ว ก็หาเน็ตไม่ได้เลยอ่า เอาเป็นว่า สรุปการไปเยือนเมืองนอกเอาทีเดียวเลยละกัน ... อ้อ ยังไม่ได้เอาภาพจากกล้องมาลงหนะ อ่านแห้ง ๆ ไปก่อนละกัน :P
posted by Tunococ @ 11:26 AM
14 comments
![]()
![]()
ตื่นตอนเช้า กินอาหารเช้า แต่งตัว ... พอถึงเก้าโมงก็มีคนมารับไปโรงงาน
posted by Tunococ @ 11:50 PM
3 comments
![]()
![]()
กะจะเอารูปมาให้ดูด้วย แต่ว่าลืมเอาสายต่อกล้องมา เลยเอาลงเครื่องคอมพ์ไม่ได้ T_T เล่าให้ฟังเป็นตัวอักษรอย่างเดียวก่อนละกัน
posted by Tunococ @ 4:38 PM
5 comments
![]()
![]()
วันที่ 6 - 20 เดือนนี้ จะไป Rome กับ Frankfurt หละ ไว้จะถ่ายรูปมาให้ดูกันบ้าง ... (กลับมา จะ update ละ)
posted by Tunococ @ 5:39 PM
0 comments
![]()
![]()
posted by Tunococ @ 7:43 PM
0 comments
![]()
![]()
posted by Tunococ @ 11:57 AM
8 comments
![]()
![]()
ประเด็นมันอยู่ที่ว่า หลาย ๆ คน คิดว่า คนที่จะเข้าวิศวะจุฬา ฯ ได้เนี่ย จะต้องขยันเรียนสุด ๆ (อย่างน้อยก็ ตอน ม. ปลาย) และคนที่จะได้เกียรตินิยมอันดับ 1 เนี่ย มันต้องขยันโคตร ๆ ๆ ๆ
posted by Tunococ @ 12:59 AM
4 comments
![]()
![]()
ไปมาเมื่อวันเสาร์ จะบอกว่า
posted by Tunococ @ 3:53 PM
2 comments
![]()
![]()
blog ที่เกิดใหม่ตอนปีใหม่ มีดังนี้...
posted by Tunococ @ 9:59 PM
3 comments
![]()
![]()
posted by Tunococ @ 7:26 PM
5 comments
![]()
![]()
posted by Tunococ @ 2:15 AM
0 comments
![]()
![]()
เขียนบ่อย ๆ ไม่ไหวแล้วอะ ... งานมหาศาล ... หยั่งงี้ยังเรียกว่าว่างงานได้มั้ยเนี่ย
posted by Tunococ @ 1:51 PM
0 comments
![]()
![]()
เพื่อให้เห็นภาพ ว่าที่ผ่าน ๆ มา มันเป็นอะไร คราวนี้ มาลองสร้าง Virtual Machine กันเถอะ ... มาสรุปสิ่งที่ Virtual Machine ควรจะมีก่อน ... ครั้งนี้คิดสำหรับ process เดียวก่อนนะ
posted by Tunococ @ 6:49 PM
2 comments
![]()
![]()
ลองสมมติว่า เราเขียนโปรแกรมมา คอมไพล์เสร็จ มันเป็นก้อน object code หน้าตาคงที่ ...
posted by Tunococ @ 7:40 PM
1 comments
![]()
![]()
Return Value Problem
int Succ(int a)
{
return a + 1;
}
Succ:
REF a -2
PUSH a
LOAD
PUSH 1
ADD
RETURN
int Double(int a)
{
int x = a;
return a + x;
}
Double:
REF a -2
VAR 1
REF x 1 PVAR x
PVAR a
LOAD
STORE
PVAR a
LOAD
PVAR x
LOAD
ADD
??? ??? RETURN
Double:
REF a -2
PUSH 0 REF rv 1 VAR 1
REF x 2 PVAR x
PVAR a
LOAD
STORE
PVAR rv PVAR a
LOAD
PVAR x
LOAD
ADD
STORE FVAR RETURN
Double:
REF a -2
VAR 1
REF x 1 PVAR x
PVAR a
LOAD
STORE
PVAR a
LOAD
PVAR x
LOAD
ADD
RETURN
posted by Tunococ @ 6:44 PM
14 comments
![]()
![]()
Literal
int main()
{
char *msg = "ABC";
printf("%s\n", msg);
return 0;
}
main:
VAR 1
REF msg 1
PVAR msg PUSH literal0
STORE
PUSH literal1
PVAR msg
LOAD PUSH printf
CALL
FVAR PUSH 0
RETURN
literal0: "ABC"
literal1: "%s\n"
printf:
...
0000h: PUSH 0
0002h: PBASE
0004h: PUSH 1
0006h: SUB 0008h: PUSH 0024h
000Ah: STORE
000Ch: PUSH 0025h
000Eh: PBASE
0010h: PUSH 1
0012h: SUB 0014h: LOAD
0016h: PUSH 0026h
0018h: CALL
001Ah: PUSH 0
001Ch: MUL
001Eh: ADD
0020h: PUSH 0
0022h: RETURN 0024h: "ABC"
0025h: "%s\n" 0026h: ...
posted by Tunococ @ 4:47 PM
0 comments
![]()
![]()
จริง ๆ แล้ว ภาษา assembly มันก็ภาษาเครื่องแหละ แต่มันเขียนสะดวกกว่านิดนึง ... อะไรที่เราควรจะกำหนดเพิ่มไว้ก่อนหละ? ก็เรื่อง label กับ ตัวแปรไง
void f()
{
int x;
int y;
x = 0;
y = x + 500;
}
f: VAR 2 PBASE PUSH 1 SUB PUSH 0 STORE PBASE PUSH 2 SUB PBASE PUSH 1 SUB LOAD PUSH 500 ADD STORE ... FVAR PUSH ค่ามั่ว ๆ อะไรก็ได้ RETURN PBASE PUSH 2 SUB f: VAR 2 REF x 1 (บอกให้ x = BP - 1) REF y 2 (บอกให้ y = BP - 2) PVAR x PUSH 0 STORE PVAR y PVAR x LOAD PUSH 500 ADD STORE ... FVAR PUSH ค่ามั่ว ๆ อะไรก็ได้ RETURN int f()
{
int x;
int y;
do {
x = ReadFromSomewhere();
y = ReadFromSomewhere();
} while (x != y);
return 0;
} f:
VAR 2 REF x 1
REF y 2
loop: PVAR x
PUSH ReadFromSomewhere CALL
PVAR y
PUSH ReadFromSomewhere CALL
PVAR x
LOAD
PVAR y
LOAD
SUB
PUSH loop JNZ
FVAR PUSH 0 RETURN
1234h: PUSH
1236h: PUSH
1238h: PBASE
123Ah: PUSH 1
123Ch: SUB
123Eh: PUSH 5678h 1240h: CALL
1242h: PBASE
1244h: PUSH 2
1246h: SUB
1248h: PUSH 5678h 124Ah: CALL
124Ch: PBASE
124Eh: PUSH 1
1250h: SUB
1252h: LOAD
1254h: PBASE
1256h: PUSH 2
1258h: SUB
125Ah: LOAD 125Ch: SUB 125Eh: PUSH 1238h 1260h: JNZ
1262h: PUSH 0 1264h: RETURN
posted by Tunococ @ 2:52 AM
0 comments
![]()
![]()
ต่อจาก มาลองออกแบบ Abstract Instruction Set กัน (ตอนแรก) เลยนะ
void f()
{
int x;
int y;
x = 0;
y = x + 500;
...
} f: PUSH ค่าเริ่มต้นของ x PUSH 0 MUL ADD void f()
{
int* x;
x = new int;
...
} f: VAR 1 (สมมติว่าขนาดของ pointer = 1)
posted by Tunococ @ 11:37 PM
0 comments
![]()
![]()
ขอโทษล่วงหน้า ถ้าทำให้ใครบางคนอ่านเรื่องนี้ไม่รู้เรื่องตั้งแต่ต้น ...
posted by Tunococ @ 1:26 AM
2 comments
![]()
![]()
เนื่องจาก การคิดเลขในฐานอะไรก็เหมือนกันหมด แต่เราอยากทำในกรณีที่มันเป็นฐาน 2 เพราะว่า คอมพิวเตอร์มันเป็นฐานสอง ... มาดูกันว่า การบวกเลขฐานสอง ทำกันยังไงนะ

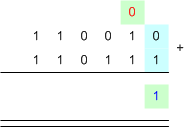
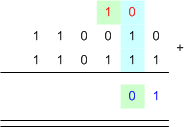

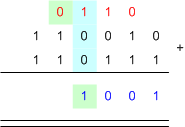
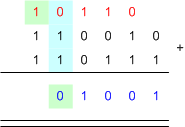

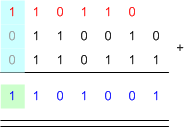
posted by Tunococ @ 12:37 AM
1 comments
![]()
![]()
ที่ผ่าน ๆ มา เราก็รู้กันไปเรียบร้อยแล้วเรื่อง การแปลงฐานเลข คราวนี้ก็ ขอตั้งข้อกำหนดเบื้องต้นไว้นิดนึงนะ คือ
posted by Tunococ @ 11:59 PM
0 comments
![]()
![]()
I'm an enthusiastic learner of math, formal languages, and music. I work as a software engineer for a living. I love playing the piano, learning math, playing games, thinking about making games, snowboarding, skiing, and climbing.
จำนวนผู้ที่เคยเข้ามาเยี่ยมชม:

